Recently, Toronto Public Library ran their second Hackathon, and I was asked to a) post the data on our open data server and b) be a mentor at the Hackathon (I'm a TPL employee and a computer geek). The group I was assigned to help ("Bridging the Digital Divide") came up with a simple and non-technical solution to better distributing TPL's user-borrowable wireless access points, and I had a fair amount of time to work on my pet project.
Two of the data sets we've made available are MARC dumps of our entire catalogue for two different dates: 2015-10-25 and 2016-09-07. I was interested in seeing what items had been removed from the catalogue in that time, and then looking at the publication dates of the removed items. My assumption was that the dates of removed items would form a bell curve centred around the year 2000 or 2005. The interest was to find out if I was correct about the shape and location of the graph, and if not, why not.
The first step was to find a (programming) library: happily, there seem to be at least one MARC library for every programming language. I chose PyMARC as I prefer Python. It has its own eccentricities, but is generally very simple to work with.
I made a lot less progress than I expected even though I had a fair bit of time to work on this project during the Hackathon. This is because catalogue data is so far from machine-readable that you have to laugh - because otherwise you'd cry. Trying to programmatically examine 1.8 million catalogue records requires clean data, and this ain't that. It's human-readable, but it's horrible to process.
Here are a bunch of examples, getting progressively worse for machine interpretation. These are culled from the MARC 260c or (in more recent records) the MARC 264c fields.
2002. c1998. p1991. [1931] 1827] 1914- 1979?] [1966?] [pref. 1898]. cop. 2001 [[1968]
Up 'til now, you might think you could handle this with a regex looking for four digits, although that throws away the subtlety of the trailing dash or question mark. Not a hope:
1990, c1988. [1994], c1993. min kuo 77 [1988] MDCCLX [i.e. 1760] c1997-<c1998> 1959-61. [1971, i.e. 1972] 1967 [i.e. 1968] 1941, c1929. [2003?], 1958. 1928-[47] [18-?] [19--]
Most of this is legitimate cataloguing, although some of it is typos or cataloguer eccentricity. Even if it was all clean and legit, dealing with every variation within a program would be prohibitively time-consuming. And this is only attempting to parse one field of the approximately 1000 that MARC provides (although only about 50-60 are in common use).
One of the other gotchas was that I looked at the beginning of the data file initially and saw that the publication (or is it copyright?) date was in field 260$c. (When you have 1.8 million records, you don't eyeball all of them.) This inevitably caught me: cataloguing standards changed a few years ago (not sure when), and the correct field for pub date is now 264$c. But it wasn't a clean shift: 260$c is still used - presumably mostly when the item is an older one that's being copy-catalogued (it's a library thing - if you don't understand, don't worry about it ... it's not important). Here's the count of 260$c fields in the catalogue as of September 2016:
55762 2012 35990 2013 14727 2014 1360 2015 11 2016
Not bad, really, for an organisation the size of TPL ...
So the logic I've worked up is ... well, appalling, but without investing months in development for a single MARC subfield, I needed to do something:
- regex match four digits
- if no match, discard
- if more than one match, discard
- I'm considering if there's two matches and they're ten or less years apart, just averaging the two
This (without the averaging plan) drops about 250,000 records. Even given the size of the catalogue, that's a lot.
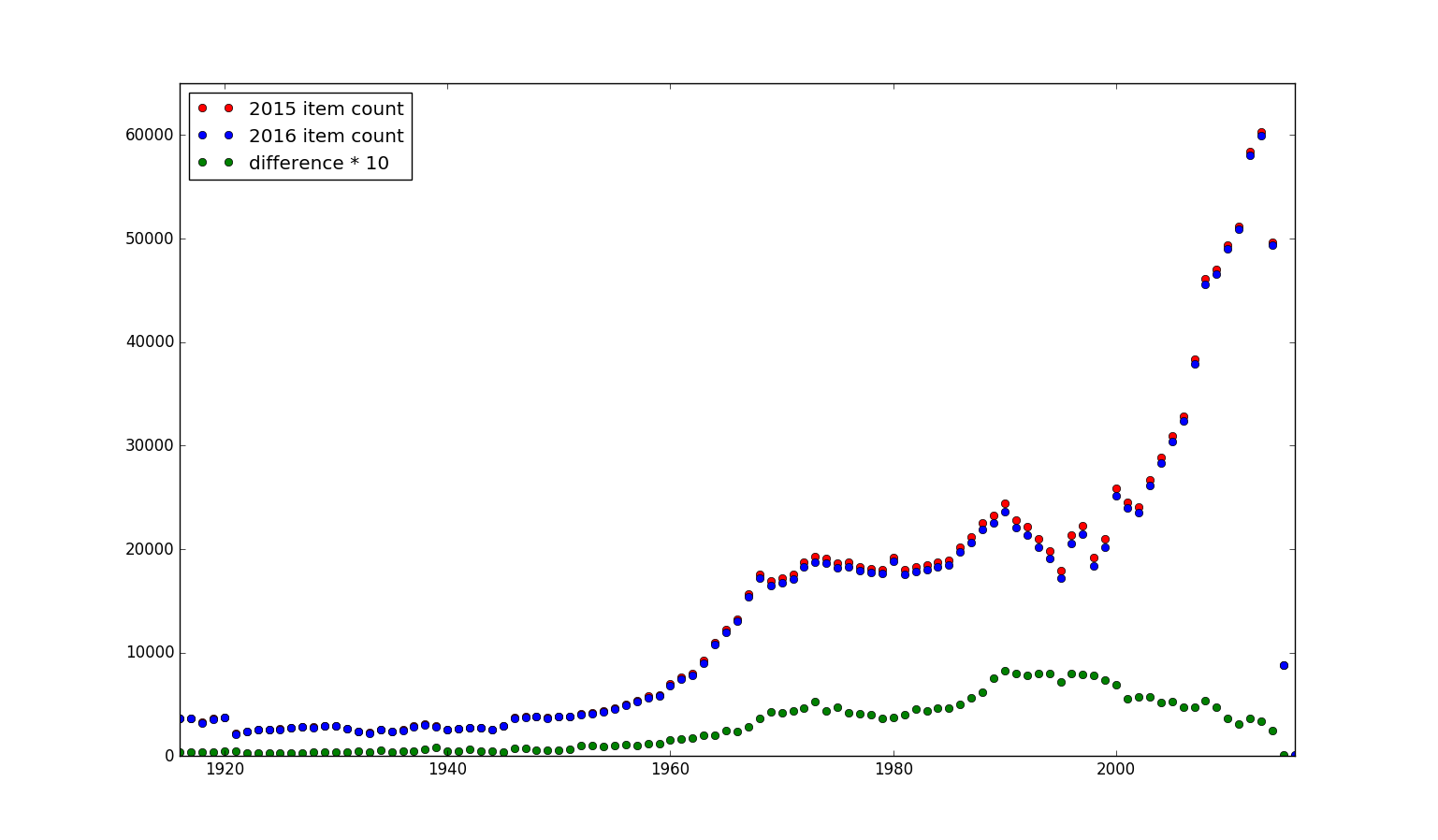
I find this graph pretty interesting. I'd expect the item count for every year to be less in 2016 than it was in 2015 (this is essentially true), except of course for the current year and possibly the previous year (this is where we're adding to our collection ... and it's true, but not in as large quantities as I expected). There's a big dip in acquisitions from 1993 to 1999. The green dots are the difference between the two different years' holdings multiplied by ten (otherwise it was all on the bottom edge of the graph). So not exactly a bell curve (it could be argued I'm only wrong about that because of the drop in purchasing), and the not-a-bell-curve peaks at 1990, so I was off the peak by more than a decade. Notice that this isn't strictly the difference I was hoping to get: I wanted to look at just discards, while this calculation is based on how many less titles we hold in a given year (it might not be the same as some books could have been acquired in the given year ... but this should be a very close approximation).
This is all probably massively inaccurate: I would love it if someone else downloaded that same data and started poking and prodding it. Please let me know if you do.